
The gaming industry is undergoing significant growth, with AI-driven interactive experiences setting new standards. Anuttacon, an independent research lab, is committed to developing humanistic general intelligence that enables seamless, real-time interactions across text, voice, visuals, and more. Their mission is to create multimodal AI capable of genuine emotional understanding and expressive communication—technology that both thinks and feels.
When preparing to launch their highly anticipated game, “Whispers from the Star,” Anuttacon encountered a common yet critical industry challenge: managing massive, unpredictable traffic spikes while making sure of optimal performance across multiple Amazon Web Services (AWS) Regions and addressing GPU capacity constraints.
In this blog, we explore how Anuttacon successfully implemented a scalable architecture for “Whispers from the Star” using AWS services. The solution is especially relevant for gaming companies facing similar issues with unpredictable traffic and GPU resource limitations. Game developers, architects, and technical leaders working on AI-enhanced gaming applications can find valuable architectural patterns and best practices in this discussion.
The challenge: beyond traditional scaling
Traditional scaling approaches fall short when dealing with the unique demands of modern gaming workloads, particularly those enhanced with AI features. Anuttacon’s “Whispers from the Star” presented several interconnected scaling challenges that pushed conventional methods to their limits.
Dynamic traffic patterns
The game experienced massive traffic spikes during the initial launch, often reaching 10-50x normal capacity. This peak demand makes it economically unfeasible to reserve all necessary instances and storage in advance. Daily engagement cycles create varying traffic patterns as players engage with AI-enhanced gameplay features at different times throughout the day, making static capacity allocation inefficient.
Resource constraints
AI-enhanced features need GPU instances, which have varying availability across different AWS Regions. The team needed to provision infrastructure within minutes to maintain player experience during traffic bursts while implementing dynamic scaling to avoid over-provisioning during off-peak hours and make sure of capacity during peaks.
Technical requirements
The architecture needed to minimize downtime to make sure that players had a consistently good experience. This necessitated uniform performance regardless of geographic location or underlying infrastructure constraints.
The solution: stateless multi-Region architecture
Anuttacon implemented a sophisticated multi-Region architecture that uses stateless service designed to enable flexible scaling and capacity management across AWS Regions.
Game service architecture
“Whispers from the Star” consists of three major gaming service components: core game service, renderer service, and inference service. They work together to deliver a complete gaming experience in the following ways, also shown in the following figure.

The core game service handles essential functions, such as user login, payment processing, and game state management. This service maintains user data and game progression, necessitating careful state management and data consistency.
The renderer service processes graphics and visual elements, generating the visual output that players see. This service is designed to be stateless, which allows it to run on any available infrastructure without needing specific data or configuration.
The inference service powers the AI-enhanced features of the game, running machine learning (ML) models to generate intelligent responses and behaviors. Like the renderer service, the inference service is designed to be stateless, enabling it to operate on any available compute resources.
The design choice of making both services completely stateless enables them to run on any available Amazon Elastic Kubernetes Service (Amazon EKS) cluster in any AWS Region without necessitating data migration or specific configuration. When capacity constraints occur in one AWS Region, workloads can seamlessly move to AWS Regions with available resources.
Architecture components
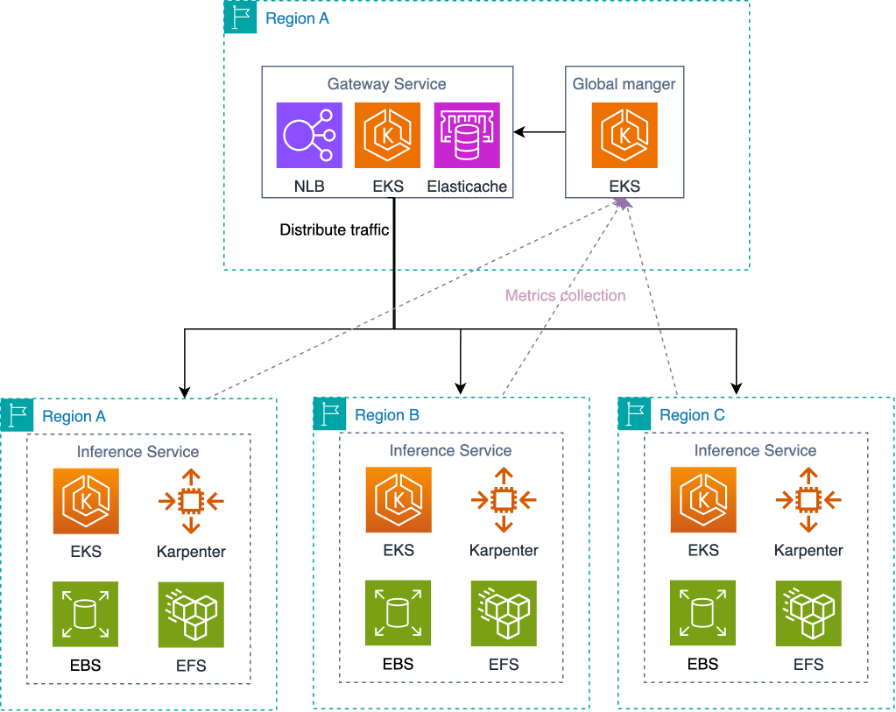
The solution consists of three integrated components working together to provide seamless scaling and capacity management, as shown in the following figure.
{kind=link}
Regional EKS clusters
Each AWS Region contains an independent EKS cluster that operates autonomously, scales independently based on local demand, and maintains its own capacity pools and resource allocation. These clusters include optimized storage configurations as part of their setup to enable faster resource provisioning for the stateless services.
Each Regional cluster uses Amazon EKS for managed Kubernetes orchestration with integration with AWS services for seamless scaling and support for diverse workload types such as both CPU and GPU intensive applications.
Karpenter provides intelligent node provisioning that automatically selects optimal instance types based on workload requirements, provisions nodes within minutes rather than needing manual intervention, and supports diverse instance families to avoid capacity constraints.
Gateway service
The gateway service manages the routing of incoming requests across all Regional clusters. It continuously monitors the health status of backend services across different AWS Regions through active health checks. When any Regional cluster shows signs of abnormality or degradation, the gateway service rapidly detects these issues and automatically removes the unhealthy services from the routing pool. It distributes traffic based on real-time usage metrics and health status across AWS Regions, which makes sure of optimal load distribution and performance. The gateway service makes intelligent routing decisions to direct player requests to the most appropriate healthy regional cluster based on the current capacity, performance metrics, and service health status.
Global manager
The global manager provides intelligent orchestration and capacity management across all regional clusters and their constituent Availability Zones (AZs). It continuously monitors usage and capacity constraints at both the Regional and AZ levels, which automatically rebalances each cluster’s target capacity to optimize resource allocation and maintain performance standards. Managing resources at the AZ granularity enables the global manager to make more precise scaling decisions and better handle localized capacity constraints. The global manager works in coordination with the gateway service to make sure that both routing decisions and capacity planning are aligned across AWS Regions and AZs.
Addressing technical implementation challenge: inference cold start
One of the most significant challenges in the inference service is the cold start problem. AI models and their associated containers are typically large, often hundreds of gigabytes in size. When new instances launch, they must download these large container images and AI models before they can begin serving inference requests. Without careful optimization, this process can take 10+ minutes, creating unacceptable delays during traffic spikes when rapid scaling is most critical.
Previous container scaling for the inference workloads solution follows a predictable but slow pattern. First, Amazon Elastic Compute Cloud (Amazon EC2) instances launch, which typically takes 30-60 seconds. Then, containers must download large images containing AI frameworks, libraries and models from Amazon Elastic Container Registry (Amazon ECR), often needing 10-15 minutes for inference workloads with large model files. Finally, containers initialize and load models into memory, adding another 10-15 minutes. The total time can range from 20-30 minutes, which is unacceptable for gaming workloads experiencing sudden traffic spikes.
Addressing the implementation challenge, Anuttacon developed a multi-faceted approach to address the cold start problem for their inference service. Its solution involved pre-building custom Bottlerocket Amazon Machine Images (AMIs) with embedded containers to reduce the container download time, using Amazon EBS Provisioned Rate for Volume Initialization to speed up Amazon EBS initialization, and using Amazon Elastic File System (Amazon EFS) to load large ML models.

Custom Bottlerocket EBS Snapshot serve as a critical enabler for this approach by leveraging the data volume feature of the Bottlerocket operating system. This allows container images to be prefetched rather than downloaded from ECR during deployment, eliminating download time and improving startup performance.
Amazon EBS Provisioned Rate for Volume Initialization further accelerates this process by ensuring these data volumes are created and initialized within predictable timeframes. This AWS feature significantly reduces the time required to create fully performant EBS volumes from snapshots, enabling faster instance startup times during scaling events.
During peak demand, the customer must create 200 EBS volumes per minute to scale out effectively. Using Amazon EBS Provisioned Rate for Volume Initialization at the maximum rate of 300 MiB/s per volume, EBS ensures that data volumes containing prefetched container images (187GB of actual data) are ready within 6 minutes. This optimization proves particularly valuable since high-performance storage is only required during the initial model loading phase.
The architecture also utilizes Amazon EFS as a high-performance file system for frequently accessed AI models. By combining Bottlerocket’s data volume prefetching capability with EBS Provisioned Rate for Volume Initialization and Amazon EFS for large model file storage, the system achieves substantial performance improvements. EBS loads the prefetched container image data (187GB) within 6 minutes while simultaneously loading additional AI models (50GB) from EFS in parallel. This parallel loading approach ensures total time from container start to model completion remains under 7 minutes—a significant improvement over the previous implementation.
Cross-Region scaling best practices
Anuttacon implemented several battle-tested practices to make sure of reliable scaling across AWS Regions. Multi-Region deployment provides geographic distribution for fault tolerance and capacity availability. Diversified instance families spread workloads across multiple EC2 instance types to avoid capacity constraints in any single instance family. A warm pool buffer maintains pre-warmed instances that provide time for more scaling to occur during traffic spikes. Retry mechanisms with Karpenter provide automatic retry logic for node provisioning failures. Backpressure and queuing implement intelligent traffic management to handle load spikes gracefully without overwhelming backend systems.
Key takeaways for designing gaming infrastructure
This architecture demonstrates several crucial principles for modern gaming workloads.
Stateless service design
The key architectural principle is designing services to be stateless wherever possible. Stateless services can run on any available infrastructure without needing data migration or specific configuration, enabling true multi-Region flexibility and rapid scaling in response to capacity constraints.
Storage optimization for large AI models
Pre-loading containers into custom AMIs and EBS Snapshots, using Amazon EBS Provisioned Rate for Volume Initialization to load the containers and using Amazon EFS to load models can significantly improve scaling performance for inference workloads. This approach addresses the cold start problem that traditionally slows AI-enhanced gaming applications.
Multi-Region resource balancing
Intelligent traffic distribution based on real-time capacity enables better resource usage and consistent player experience. This approach is particularly valuable for GPU workloads where capacity constraints vary significantly by AWS Region.
Conclusion
Anuttacon’s success with “Whispers from the Star” showcases how thoughtful architecture design can address the unique challenges of modern gaming workloads. Focusing on stateless service design and using AWS capabilities, particularly Amazon EBS Provisioned Rate for Volume Initialization, to address cold start challenges enabled them to create a solution that scales efficiently, manages costs effectively, and delivers exceptional player experiences.
The gaming industry’s evolution toward AI-enhanced experiences and global player engagement necessitates infrastructure that can adapt quickly to changing demands. This architecture pattern provides a proven blueprint for gaming companies facing similar scaling challenges.
To learn more about Amazon EBS Provisioned Rate for Volume Initialization, visit the AWS News blog.